计算机体系结构基础知识介绍之动态调度 Tomasulo算法(二)与计算机系统服务
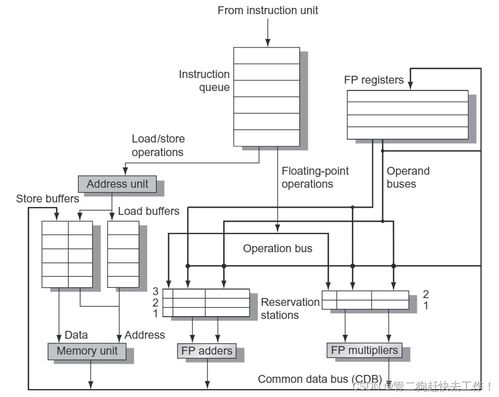
在上一部分的介绍中,我们探讨了Tomasulo算法的基本原理、其核心组件——保留站、公共数据总线(CDB)以及寄存器重命名机制,并分析了它如何通过动态调度解决数据冒险,特别是写后读(RAW)冒险,从而显著提升指令级并行性。本部分将深入探讨Tomasulo算法在处理更复杂控制流和系统交互时的考量,并简要关联其在现代计算机系统服务中的角色与影响。
一、Tomasulo算法中的控制冒险与分支预测
尽管Tomasulo算法卓越地处理了数据冒险,但它本身并不直接解决控制冒险(由分支指令引起)。在早期的动态调度设计中,遇到分支指令时,处理器可能需要停顿(stall),直到分支方向被确定,这会严重浪费处理器资源。
为了最大化性能,现代采用Tomasulo思想的处理器普遍集成了分支预测(Branch Prediction)单元。其工作流程增强如下:
- 预测执行:取指阶段,分支预测器会预测分支的方向(跳转或不跳转)和目标地址。处理器基于预测继续前瞻性地取指和发射后续指令,形成一个“推测执行”的流。
- 带标记的调度:所有在分支预测后发射的指令都被标记为“推测性”的。Tomasulo算法像往常一样对这些指令进行调度、执行和结果转发,但这些结果在分支确认正确之前不会最终提交(写回架构寄存器或内存)。
- 分支解决与恢复:当分支指令的实际方向被计算出来时(在ALU执行后),会进行验证。如果预测正确,所有推测性指令的结果被“提交”,状态转为有效。如果预测错误,则必须进行恢复操作:清空该分支之后所有推测执行的指令在保留站、重排序缓冲区(ROB)和负载/存储队列中的状态,并从正确的路径重新开始取指。
这种结合了分支预测的Tomasulo算法,构成了现代乱序执行(Out-of-Order Execution)核心的基础,它允许处理器在存在不确定的控制流时,依然能保持执行流水线的充盈。
二、内存访问冒险与存储队列
Tomasulo算法最初主要关注寄存器操作。对于内存操作(Load/Store),会引入新的冒险:
- 写后读(RAW)内存冒险:一条Store指令写入内存后,后续的Load指令必须读到这个新值。
- 写后写(WAW)与读后写(WAR)内存冒险:虽然寄存器重命名解决了寄存器层面的这些冒险,但内存地址在运行时才可知,因此需要特殊机制。
为此,扩展的Tomasulo实现引入了加载队列(Load Queue) 和存储队列(Store Queue):
- 顺序发射,乱序执行:Load和Store指令按程序顺序进入各自的队列。
- 地址计算与冒险检测:当Load指令的地址计算完成后,它需要检查存储队列中所有地址未定的Store指令。如果存在地址冲突(指向同一内存单元)且该Store指令的值已就绪,则Load可以直接从存储队列中获取该值(存储转发,Store Forwarding)。这解决了RAW冒险并提升了性能。
- 顺序提交:内存操作必须按照程序顺序提交(写回内存),以维持内存访问的顺序一致性(Sequential Consistency)或更宽松的内存模型所要求的顺序。这通常由一个重排序缓冲区(ROB) 来管理,确保指令(包括Load/Store)的退休(Retirement)是按序的。
三、Tomasulo算法与计算机系统服务
Tomasulo算法及其演进形式是现代微处理器(CPU)的核心调度机制,它直接支撑着计算机系统的多项关键服务:
- 计算服务的高效执行:操作系统调度一个进程或线程后,其指令流被送入CPU核心。Tomasulo算法在硬件层面,对用户程序和系统内核代码一视同仁地进行动态调度、乱序执行,最大化地利用了执行单元,提高了系统吞吐率和单个任务的响应速度。这是最基础的计算服务。
- 虚拟内存与中断响应的交互:当执行中的指令触发缺页异常(Page Fault)或遇到I/O中断时,处理器必须能够精确地暂停或保存当前状态。在乱序执行的上下文中,这要求处理器具备精确异常(Precise Interrupt)的能力。这与Tomasulo算法扩展使用的重排序缓冲区(ROB) 密切相关。ROB确保在异常或中断发生时,只有异常指令之前的指令被提交,之后的所有推测执行指令被抹去,从而将架构状态恢复到一致的点,便于操作系统进行现场保存和后续恢复。
- 多核/多线程同步的底层支持:在多核系统中,内存一致性协议(如MESI)需要与核心内的存储队列协同工作。当核心执行一个存储操作时,该操作在最终提交前可能位于其存储队列中。缓存一致性协议在此时介入,处理其他核心对此地址的访问请求。Tomasulo机制中内存操作的延迟提交和排序,为实现高效的缓存一致性和同步原语(如锁、屏障)提供了硬件基础。
- 性能监控与系统优化:现代CPU内置的性能监控计数器(PMCs)可以统计诸如“保留站满周期数”、“分支预测失误次数”等事件。这些直接反映Tomasulo算法各部件效率的指标,为操作系统调度器(选择更适合乱序执行的线程)、编译器(优化指令序列)乃至虚拟机监视器(VMM)提供了关键的底层反馈,助力系统级的性能优化和资源管理。
###
Tomasulo算法不仅仅是一个解决数据冒险的巧妙设计,它与分支预测、重排序缓冲区、内存队列等组件协同,构成了现代高性能处理器乱序执行引擎的支柱。从单纯的指令调度到支撑精确异常、内存一致性,它深度融入了计算机系统服务的方方面面。理解Tomasulo算法,不仅有助于把握CPU微架构的核心,也为理解操作系统、并发编程等上层系统如何与硬件交互提供了坚实的底层视角。正是这些精密的硬件机制,默默支撑着我们每天依赖的快速、可靠的计算服务。
如若转载,请注明出处:http://www.jiaoshibiji.com/product/55.html
更新时间:2026-06-19 02:39:31